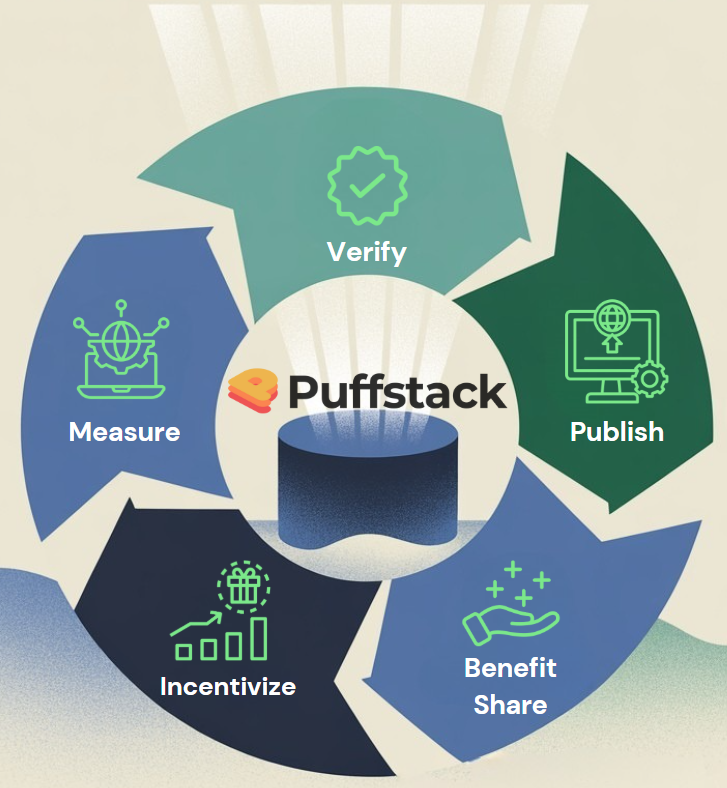
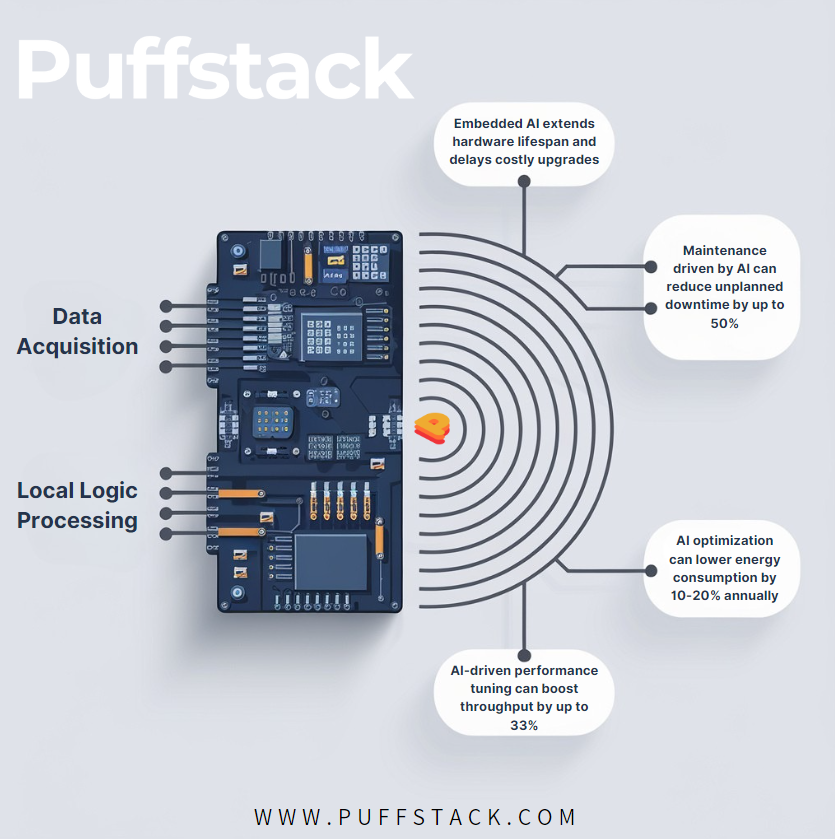
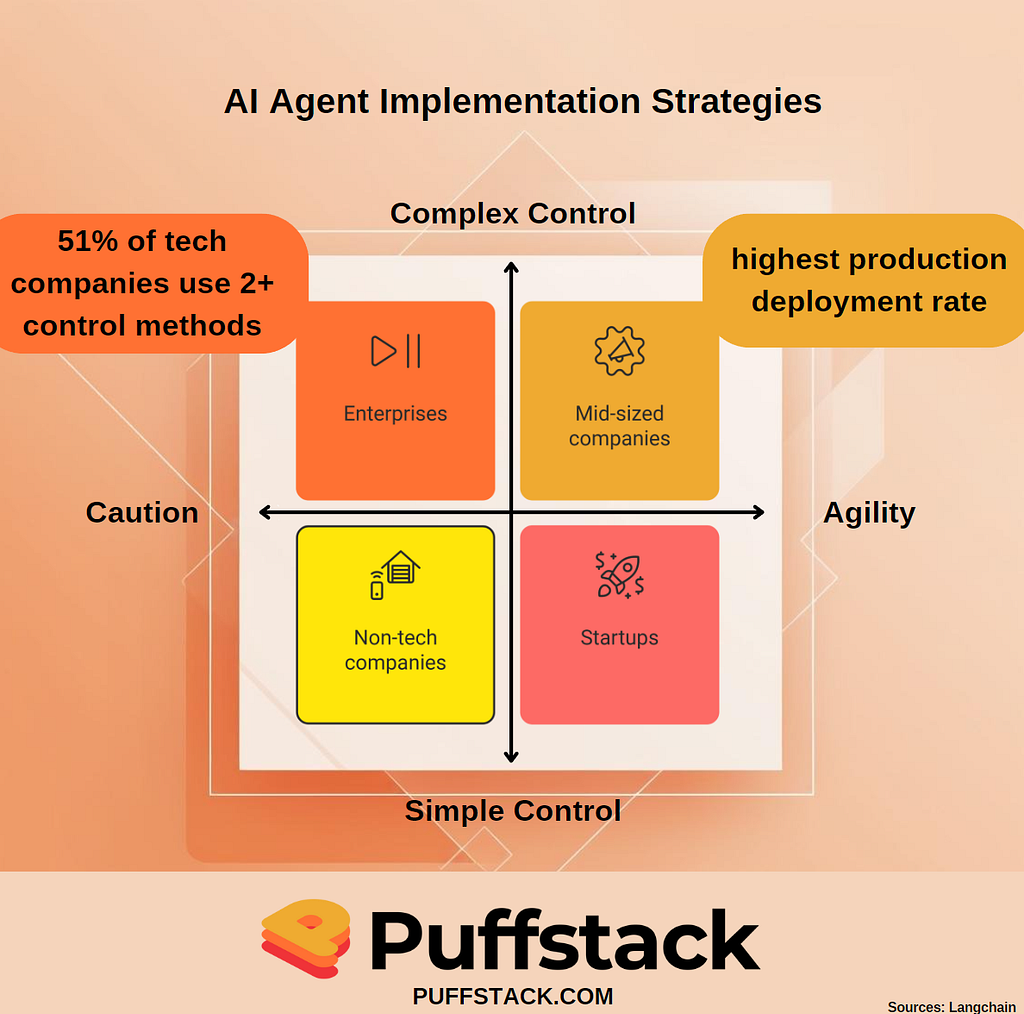
software-development software-engineering
Agents of Industry: From Signal to Action
Industrial performance depends on turning operating context into clear decisions. Most industrial environments already have the signals: flow, pressure, temperature, vibration, chemistry, alarms, even
Read